AI Product Data Enrichment: Turning Raw Catalogs into Machine-Readable Commerce Engines

From Spreadsheets to Intelligence
AI product data enrichment transforms raw catalogs into machine-readable assets using vision AI, natural language processing, and retrieval-augmented generation architectures.
The shift from manual catalog management to automated enrichment isn't just about speed. It's about scale, consistency, and the ability to maintain catalog quality as product counts grow from thousands to millions.
Manual enrichment doesn't scale. A team can process hundreds of SKUs per week with high quality. AI systems process thousands per hour while maintaining consistency across attributes, taxonomies, and validation rules.
The technical architectures enabling this are mature and proven. The question isn't whether AI can enrich catalogs. It's whether retailers understand how to implement these systems effectively.

The Technical Stack: Vision AI, NLP, and RAG
Modern enrichment pipelines combine three core capabilities.
Vision AI for image analysis.
Computer vision models analyze product images to extract visual attributes: color palettes, patterns, textures, materials, dimensions, and style characteristics.
For apparel, this includes neckline type, sleeve length, fit silhouette, and fabric appearance. For furniture, dimensions, material composition, assembly requirements, and finish quality.
Vision models trained on millions of product images achieve accuracy rates above 90% for common attributes, with confidence scoring that flags ambiguous cases for human review.
NLP and LLMs for text extraction.
Large language models analyze product titles, descriptions, and specifications to identify explicit attributes (stated directly) and implicit attributes (inferred from context).
Techniques include zero-shot prompting for quick deployment, few-shot learning for category-specific tuning, and fine-tuning on labeled datasets for maximum accuracy. Fine-tuned models achieve F1-scores above 92% on benchmark extraction tasks.
The advantage of generative models over rule-based extraction is handling ambiguity, multilingual content, and incomplete data. They infer likely values when explicit statements are missing.
RAG for knowledge grounding.
Retrieval-Augmented Generation addresses the hallucination problem in pure generative approaches. Instead of generating attributes from scratch, RAG systems retrieve relevant information from external sources—manufacturer specifications, competitor listings, review data—and use that context to ground attribute generation.
This is critical for technical products where precision matters. A laptop's processor specifications shouldn't be guessed. They should be retrieved from authoritative sources and validated against manufacturer data.
RAG architectures reduce hallucination rates by 60 to 80% compared to pure generative approaches while maintaining the flexibility to handle diverse product categories.

The Enrichment Pipeline: Ingestion to Validation
Production enrichment systems follow a consistent architecture.
Step 1: Data ingestion.
The pipeline ingests product data from multiple sources: PIM systems, ERP databases, supplier feeds, marketplace listings, and scraped manufacturer websites.
Images, titles, descriptions, specifications, and existing attributes flow into a unified processing queue.
Step 2: Multimodal extraction.
Vision models analyze images. NLP models process text. The outputs—extracted attributes with confidence scores—get merged into a unified attribute set.
Conflicts between modalities get flagged. If the image shows a short-sleeve shirt but the description says "long sleeve," the system surfaces this for review.
Step 3: RAG-based augmentation.
For attributes with low confidence or missing data, RAG retrieves similar products, manufacturer specs, or category norms. The system uses this context to infer likely values.
Example: If 95% of "trail running shoes" have terrain_type: mixed and cushioning: moderate, the system suggests these for products missing those fields.
Step 4: Normalization and standardization.
Extracted values get mapped to standard taxonomies. "Blue," "Navy," and "Azul" all normalize to color: blue. Dimensions in inches convert to centimeters. Inconsistent formats unify.
This ensures filters work correctly and agents can match queries reliably across your catalog.
Step 5: Schema validation.
Enriched data validates against schema.org/Product standards, GS1 identifiers, and platform-specific requirements. Invalid or incomplete schemas get flagged for correction.
Step 6: Human-in-the-loop review.
High-confidence extractions publish automatically. Low-confidence attributes, flagged conflicts, and high-value SKUs route to human reviewers for validation and refinement.
This balances automation efficiency with quality control, especially for brand voice and messaging.
Step 7: Continuous monitoring and feedback.
As enriched products go live, the system monitors performance: CTR, conversion rates, return rates, and agent recommendation acceptance. Poor performers trigger re-enrichment or deeper review.
Behavioral signals feed back into the models, improving future extractions through continuous learning.
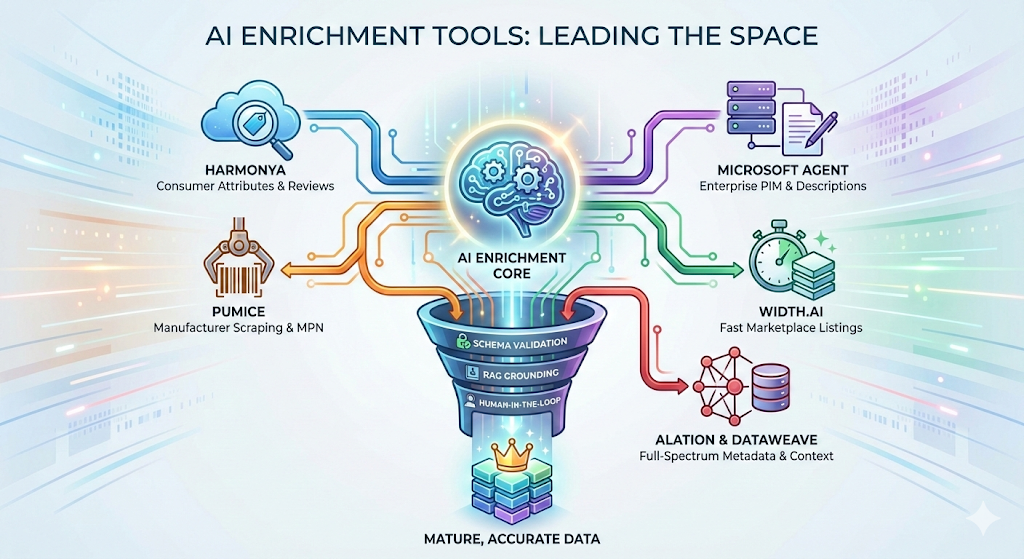
Tools and Platforms Leading the Space
Several platforms have emerged as category leaders in AI-powered enrichment.
Harmonya specializes in consumer-centric attribute extraction from reviews and marketplace listings. Their models analyze millions of product listings to identify attributes that drive search visibility and conversion, then apply those patterns to your catalog.
Microsoft's Catalog Enrichment Agent (built on Copilot Studio) ingests images and PIM data, generating brand-aligned product descriptions and attributes that write back directly to existing systems. The integration with enterprise PIMs makes it attractive for large retailers with complex tech stacks.
Pumice focuses on manufacturer site scraping and augmentation via MPN/UPC lookup. They automate vendor flat files into SEO-optimized, marketplace-ready listings by pulling authoritative data from manufacturer sources.
Width.ai offers customizable enrichment pipelines for marketplace sellers, turning flat CSV files into high-quality listings in seconds with category-specific attribute templates.
Alation and DataWeave handle full-spectrum data enrichment including metadata, context, and relationship mapping for enterprise catalogs.
What separates mature platforms from emerging tools is schema validation, RAG grounding, and human-in-the-loop workflows. Pure generative approaches without validation produce impressive demos but fail in production when accuracy matters.
Architecture Patterns That Scale
Production enrichment systems require more than just models. They need orchestration.
Batch vs. real-time processing.
Batch pipelines process catalog updates overnight or weekly, suitable for stable catalogs with infrequent changes.
Real-time pipelines enrich products as they're created or updated, essential for dynamic catalogs with frequent launches or supplier-fed inventory.
Hybrid approaches batch-process historical catalogs while handling new SKUs in real-time.
Confidence thresholds and routing.
Not all extractions are equal. Systems use confidence scores to route products through different paths.
High confidence (>95%): auto-publish
Medium confidence (80-95%): flag for spot-check review
Low confidence (<80%): full human review required
This optimizes for throughput while maintaining quality where it matters most.
Multi-stage validation.
Beyond schema validation, production systems validate against business rules: pricing constraints, brand messaging guidelines, category-specific requirements, and marketplace policies.
A product that passes technical validation might still violate brand voice or category conventions. Multi-stage validation catches these before publication.
Explainability and audit trails.
For compliance and trust, enrichment systems maintain detailed logs: which model extracted which attribute, what confidence score it received, what external sources were consulted via RAG, and whether a human reviewer modified the output.
This is increasingly important for regulatory compliance as AI systems face scrutiny over automated decision-making.
Performance Metrics That Matter
Effective enrichment systems optimize for business outcomes, not just technical metrics.
Attribute completeness rate.
Percentage of products with all required attributes for their category. Target: 95%+ for high-priority categories.
Extraction accuracy.
F1-score or precision/recall on validation datasets. Target: 90%+ for automated extraction, 95%+ post-human review.
Catalog freshness.
Median time from product creation to full enrichment. Target: <24 hours for new SKUs, <1 hour for updates.
Visibility lift.
Percentage increase in agent recommendation appearances and search impressions post-enrichment. Target: 2-5x for previously sparse listings.
Conversion impact.
Lift in CTR and conversion rate for enriched products vs. baseline. Target: 10-25% improvement.
Return rate reduction.
Decrease in returns due to better attribute accuracy and reduced purchase mismatches. Target: 10-20% reduction.
Cost per enriched SKU.
Fully loaded cost including compute, human review, and tooling. Benchmark: $0.10-$2.00 per SKU depending on category complexity.

The Future: Autonomous Enrichment Agents
The next evolution isn't just automated enrichment. It's autonomous agents that manage entire catalog lifecycles.
These agents will monitor product performance, identify underperforming listings, diagnose attribute gaps, re-enrich automatically, A/B test different attribute configurations, and optimize continuously based on conversion data.
They'll integrate with pricing engines, inventory systems, and marketing platforms to coordinate catalog strategy across channels.
Early implementations are already live. Microsoft's agent writes back to PIMs autonomously. Harmonya's system identifies conversion-driving attributes and applies them across similar products without manual intervention.
The limiting factor isn't technology. It's organizational readiness to trust autonomous systems with catalog management.
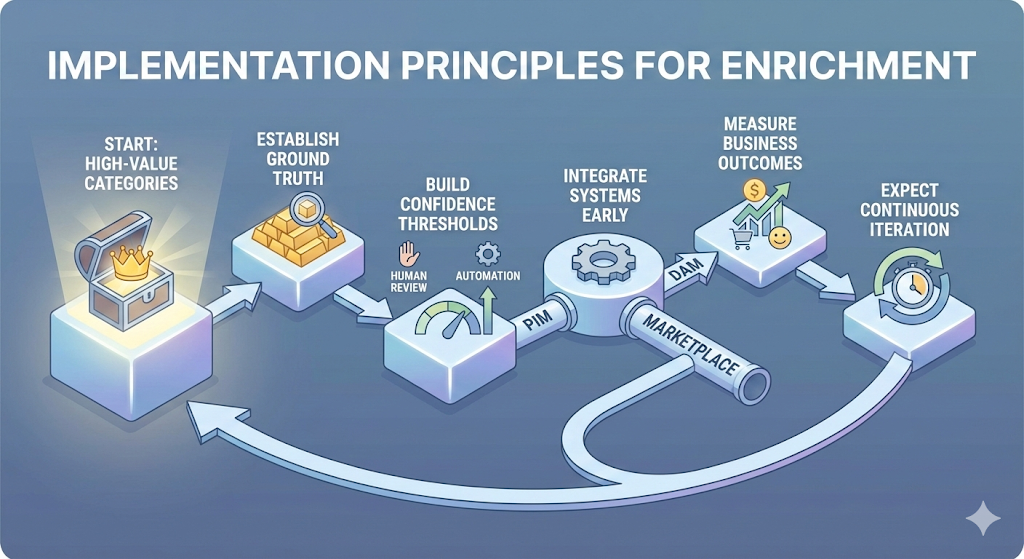
Getting Started: Implementation Principles
Teams launching enrichment initiatives should follow these principles.
Start with high-value categories. Don't try to enrich your entire catalog at once. Focus on categories with the highest revenue, fastest growth, or worst current data quality.
Establish ground truth datasets. Before automating, manually enrich 500-1000 products to expert-level quality. Use these as validation sets and fine-tuning data.
Build confidence thresholds iteratively. Start conservative with high human review rates. As accuracy proves out, increase automation thresholds.
Integrate with existing systems early. Enrichment in isolation doesn't drive value. Plan PIM, DAM, and marketplace integrations from day one.
Measure business outcomes, not just technical metrics. Extraction accuracy is table stakes. What matters is whether enriched products surface more often, convert better, and generate fewer returns.
Expect continuous iteration. Enrichment isn't a one-time project. Models drift. Categories evolve. Plan for ongoing monitoring and refinement.
The Strategic Imperative
AI-powered enrichment isn't optional anymore. It's table stakes for competing in agent-driven commerce.
The retailers succeeding in 2026 won't be the ones with the best products. They'll be the ones whose product data is complete, accurate, and structured for machine consumption.
Manual enrichment worked when catalogs had hundreds of SKUs and discovery happened through human browsing. It breaks at scale and fails completely when AI agents mediate discovery.
The technical capabilities exist. The platforms are mature. The question is whether your organization is ready to implement them.

.png)
.png)